


三分之一个世纪前,加拿大学者们提出了经典的MoE模型神经网络结构,在人类探索AI的「石器时代」中,为后世留下了变革的火种。
近十年前,美国硅谷的互联网巨擎在理论和工程等方面,突破了MoE模型的原始架构,让这个原本被置于学术高阁的理念,化身成为了随后AI竞争的导火索。
如今,后发优势再一次来到了大洋此岸,以华为为代表的中国科技企业,纷纷提出对MoE架构的优化重组方案。尤其是华为的MoGE架构,不仅克服了MoE负载不均衡及效率瓶颈的弊病,还能够降本增效,便于训练和部署。
AI之战远未终结,但正如在其他领域中「多快好省」的中国产业底色一样,大模型这棵生于西方长于彼岸的科技树,也同样会被东方智慧经手后,进化为更加普适和亲切的工具。
近期,联合网将打造《华为技术披露集》系列内容,通过一连串的技术报告,首次全面披露相关的技术细节。
希望本系列内容能为业界起到参考价值,也希望更多人能与华为一起,共同打造长期持续的开放协作生态环境,让昇腾生态在中国茁壮成长。
《华为技术披露集》系列 VOL.6 :MoGE架构
近日,华为盘古团队提出了分组混合专家模型(Mixture of Grouped Experts, MoGE)。
基于 MoGE 架构构建的盘古 Pro MoE 大模型(72B 总参数、16B 激活参数)在昇腾 300I Duo 和 800I A2 可实现更优的专家负载分布与计算效率(321 tokens/s 和 1528 tokens/s)。
在模型能力方面,盘古 Pro MoE 在最新一期业界权威大模型榜单 SuperCLUE 上交出了超能打的成绩,实现了综合能力的领先。
具体来说,和其他动辄千亿以上的大模型(如 DeepSeek-R1 具有 671B 参数)相比,盘古 Pro MoE 以 72B 总参数量达到了 59 分,千亿参数量以内大模型排行并列国内第一。并且,16B 激活参数量可以媲美其他厂商更大规模的模型。

中文技术报告:https://gitcode.com/ascend-tribe/pangu-pro-moe/tree/main
英文技术报告:https://arxiv.org/pdf/2505.21411
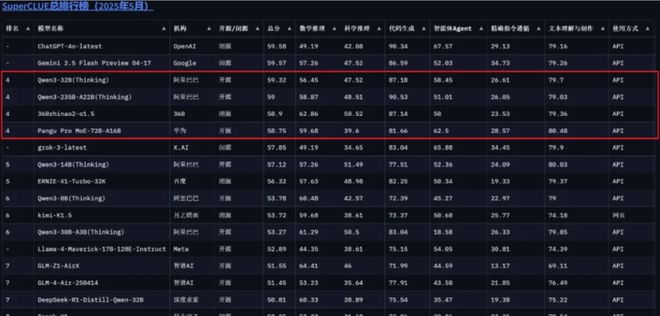
图源:https://www.superclueai.com/
他们是怎么做到的?
序言
混合专家模型已成为大型语言模型领域的革新范式 —— 近年来,模型与数据集规模呈指数级增长,而 MoE 通过稀疏激活机制(仅针对每个 token 激活部分专家子集),在维持高表达能力的同时降低计算开销,使其在大规模应用中极具吸引力。
然而,传统 MoE 架构面临的核心挑战是专家负载不均衡:当部分专家因过度专业化或 token 分配过载时,其他专家则处于低效利用状态。由于专家通常分布于多设备并行执行,MoE 模块的整体时延往往由承载最多 token 的设备决定,这种不均衡会严重损害计算效率与系统吞吐量。
针对这一行业难题,华为盘古团队(以下简称团队)推出全新盘古 Pro MoE 大模型。
该模型创新性提出分组均衡路由技术,通过硬约束的负载均衡策略,确保每个 token 在预定义的专家分组内激活等量专家,这样就天然的确保了跨设备的专家负载均衡;结合仿真优化算法,从层数、宽度、专家数等多维度优化资源分配,构建出昇腾亲和的盘古 Pro MoE 架构。同时,深度融合昇腾 300I Duo/800I A2 硬件加速架构的并行计算特性与算子级编译优化技术,实现从算法设计到系统落地的全栈创新。
实验表明,盘古 Pro MoE 在同等算力条件下推理延迟更低,和业界同规模大模型相比,通用和复杂推理综合精度领先,为超大规模模型的工业化部署提供新范式。
接下来,将系统性解析盘古 Pro MoE 的核心技术原理与工程实现路径。
昇腾原生的 MoGE 新架构
从「无序激活」到「精准协同」
传统 Top-K 路由存在无序激活的缺陷,也就是说,专家激活无限制,导致某些专家并行(EP)组负载过高(如某些组激活 4 个专家,某些组专家无激活),引发计算瓶颈和端到端延迟上升。
如下图所示,子图 (a) 展示了在专家并行度 (EP)=4 时,从 24 个专家池中选取 8 个专家的激活专家分布对比;子图 (b) 则呈现了传统 MoE 和本文所提 MoGE 两种路由机制下估计的不平衡分数分布,其中分布估计的参数设定为 N=64(总专家数)、K=8(单 token 选择专家数)、M=8(组数)、∣X∣=16(输入序列长度)。
通过可视化可观察到,传统 Top-K 路由易导致专家负载倾斜。这是基于 MoE 的大模型的行业痛点,负载不均衡导致硬件资源利用率低下,推理速度无法线性扩展,尤其在分布式训练和推理场景中问题加剧。
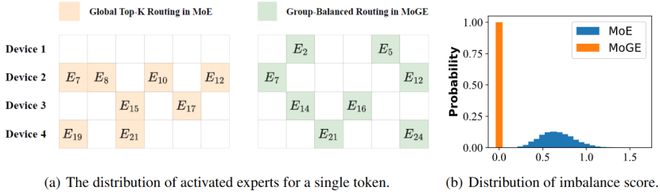
分组均衡路由
为了解决传统 Top-K 路由无序激活的问题,团队提出分组均衡路由的设计思想:强制每个 Token 在每个专家组内激活相同数量的专家(如每组激活 1 个专家,总激活数 = 组数 × 每组激活数),确保计算负载均匀分布。实现细节如下:
· 专家均匀划分为 M 组(如 64 专家→8 组,每组 8 专家);每组内独立进行 Top-K 路由(如每组 Top-2),全局激活数 = 组数 × 每组激活数。
· 分组均衡路由的优势包括:1)吞吐友好: 组间负载差异为 0,避免跨组通信瓶颈;2)动态扩展性:Batch Size 变化时负载均衡性稳定。
均衡辅助损失
团队采用 Batch 级辅助均衡辅助损失函数,其形式定义为:
其中超参数 α 控制辅助损失的强度。此处,f_i 表示批次 B 中被路由到专家 i 的 token 占比,p_i 则代表该专家在整个批次内的平均专家权重:式中 I {⋅} 为指示函数,s_i,t 表示 token t 对专家 i 的门控得分。
架构仿真
基于分组均衡路由的 MoGE 模块,团队继续通过仿真设计出昇腾亲和的模型架构。在模型设计过程中,采用分层策略,通过从粗粒度到细粒度的渐进式调优,平衡昇腾 300I Duo 和 800I A2 平台上的精度与推理效率。
该策略包含三个阶段:首先,通过粗粒度筛选依据单服务器内存带宽和时延约束确定参数范围;其次,基于领域知识对潜在模型进行候选集缩减,缩小设计空间;最后,利用算子级仿真器评估候选模型性能。该仿真器关联系统硬件参数(如 TFLOPS、内存访问带宽、内存容量及互连拓扑),并自动搜索最优并行策略。
通过分层策略与细粒度仿真,下图中标橘黄色星的模型在指定条件下展现出对昇腾 300I Duo 和 800I A2 平台的最佳亲和性,本文即采用该组超参数配置。
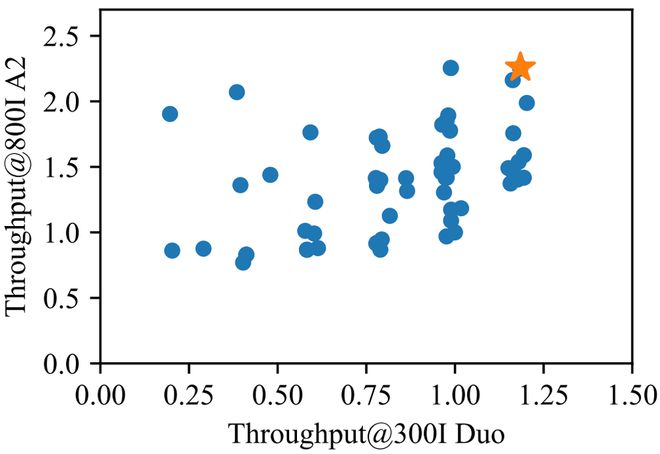
推理性能
盘古 Pro MoE 在昇腾平台上实现了混合并行与通信优化等软硬协同的系统优化、量化压缩等算法优化、MulAttention 和 SwiftGMM 等高性能算子优化,在一系列模型和系统联合优化的推理加速技术加持下,显著提升了模型的推理效率。
在昇腾 300I Duo 平台的支持下,盘古 Pro MoE 单卡吞吐可达 201 tokens/s,并通过引入 MTP 解码和多 token 优化可进一步提升至 321 tokens/s,展现出百亿级大模型推理的极致性价比。
基于昇腾 800I A2 平台,在低并发场景下模型可实现毫秒级响应;在高并发条件下单卡吞吐可达 1148 tokens/s,结合 MTP 解码等联合优化可提升至 1528 tokens/s,性能大幅领先于同等规模的 320 亿和 720 亿参数稠密模型。
盘古 Pro MoE 全面赋能业务高效落地与大规模部署,助力各类应用场景实现高性能推理体验。
模型能力
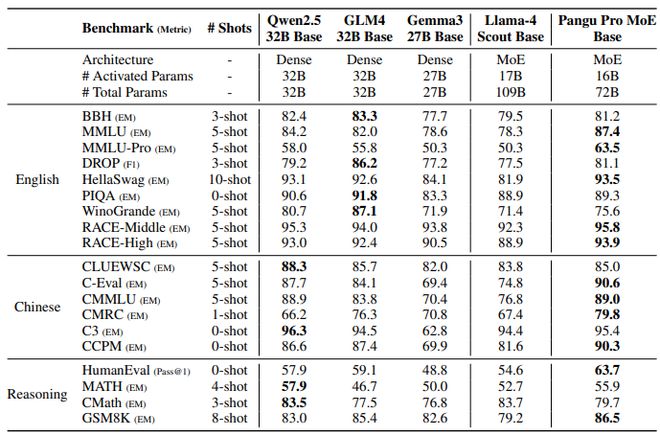
根据业界公开测评,盘古 Pro MoE 基础模型在跨语言多领域基准测试中展现出色性能:英语能力涵盖通用推理、阅读理解及常识推理;逻辑推理能力覆盖代码生成和中英双语数学问题等;中文评估则包含知识问答和阅读理解等,全面验证模型在复杂认知任务上的通用性与领域适应性。
在监督微调与强化学习的双重优化下,盘古 Pro MoE 展现出卓越的复杂推理能力。
模型在多领域评测体系进行测试:通用能力涵盖英语与中文,代码能力依托 LiveCodeBench 实时编程及 MBPP+,数学推理则通过 AIME 竞赛题、MATH-500 难题及中国数学奥林匹克 (CNMO) 验证。
对比基线选取同规模前沿模型,包括开源的稠密模型 Qwen3-32B、GLM4-Z1-32B)及 MoE 模型(Llama4 Scout),盘古 Pro MoE 在复杂推理任务上展示出同规模最优的性能。
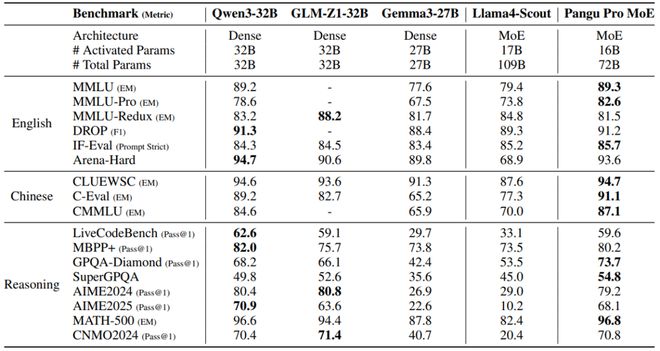
硬件效率革命
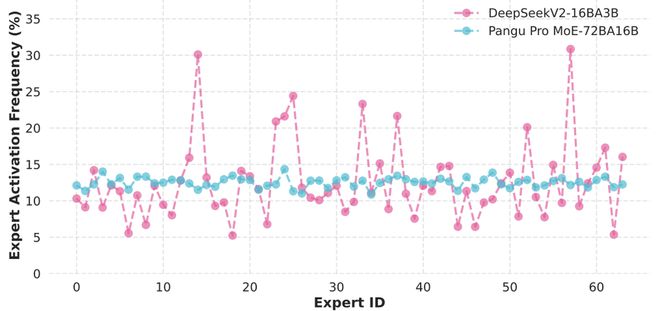
MoE 架构中的专家负载均衡与资源效率提升及模型行为稳定性增强相关。为探究此问题,本文对比分析了主流开源 MoE 模型 DeepSeek-V2 和盘古 Pro MoE 的专家负载分布。
如下图所示,DeepSeek-V2 存在显著失衡,负载最高的专家处理高达 30% 的总 token 量;呈现高度集中现象。相比之下,盘古 Pro MoE 展现出近乎均匀的分布特性,各专家处理 token 占比均约 12.5%,与理论理想值高度吻合。
这种均衡激活模式表明盘古 Pro MoE 对专家容量的高效利用,负载均衡对大规模 MoE 模型有助于实现高效可扩展性能。
让「大模型」回归实用场景
盘古 Pro MoE 的诞生,标志着大模型从「参数军备竞赛」转向「实效主义」:在企业级应用中,其动态负载均衡技术有效降低云端推理成本,支撑高并发实时场景;同时通过轻量化推理引擎适配华为昇腾系列芯片,赋能广大客户运行百亿级模型,为 AI 产业应用领域开辟新蓝海。
华为以硬核创新重新定义大模型的价值。盘古 Pro MoE 的发布,不仅是 AI 领域的一次范式革命,更将为全球企业提供「高效、普惠」的智能底座。即刻体验技术突破,携手华为共启智能新时代。
文字来源于网络。发布者:锦鲤财经,转转请注明出处:https://www.xiandaicb.cn/9928.html